, Open AI, MDR")

Künstliche Intelligenz Dumm, dümmer, GPT
Hauptinhalt
09. November 2023, 16:09 Uhr
Nach dem KI-Hype zu Beginn des Jahres machte sich im Sommer Ernüchterung breit: Power-User meldeten, die Ergebnisse von GPT seien schlechter geworden und entsprächen nicht mehr den Erwartungen. Kann künstliche Intelligenz dümmer werden? Eine deutsche Forscherin sagt nein und ja. Dröseln wir das mal auf.


- Ein Forschungspapier bestätigt den Eindruck von Nutzenden hinsichtlich Qualitätseinbußen von GPT-4
- Es gibt verschiedene Ursachen, die zu schlechteren Ergebnissen führen können
- Der Markt für Sprachmodelle steht noch am Anfang, möglicherweise gehen wir aber wieder weg von der "allwissenden KI"
Also, um ehrlich zu sein, sollte die KI an dieser Stelle restlos aus der Reserve gelockt werden. Und im besten Falle am verschachtelten Satzkonstrukt scheitern. Vergebens. "Ist es eine gute Idee, einen Artikel über KI damit zu starten, die KI zu fragen, wie man den Artikel beginnen soll?" Die Chat-Antwort des Sprachmodells ließ nicht lange auf sich warten: Aber ja doch, super Idee! "Dies kann eine interessante und einnehmende Methode sein, um das Thema einzuführen und die Leser zu engagieren." Ist wahrscheinlich auch der Grund, warum Journalistinnen und Journalisten das besonders gern machen. Ein paar Sätze später dann, etwas unvermittelt, der eindringliche Hinweis, es "sollten ethische Aspekte und Diskriminierungsfreiheit bei der Nutzung von KI-Tools berücksichtigt werden".
Jetzt wird’s spannend. Ohne etwas dergleichen in der Eingabemaske verlautet haben zu lassen, scheint das System zu wissen, worum es später im Text gehen soll. Ist dieses Ding also doch nicht dumm? Zumindest bewegt sich die Wahrnehmung der künstlichen Intelligenz immer in einem Spannungsfeld zwischen schierer Verblüffung und der Frage, ob das nun wirklich Intelligenz sein soll. Die Frage ist zwar so alt wie die KI selbst, hat aber im vergangenen Sommer noch etwas Fahrt aufgenommen, als sich die Stimmen mehrten, das Sprachmodell GPT werde plötzlich dümmer. Was war da los?
Lassen wir uns von Gitta Kutyniok auf die Sprünge helfen. Kutyniok hat an der Uni München den Lehrstuhl für mathematische Grundlagen der Künstlichen Intelligenz inne und auch sie verlässt sich im Alltag auf die Schläue der KI-Anwendungen. Zumindest auf eine: "Ich persönlich benutze sehr häufig unter anderem auf KI basierende Sprachübersetzungssysteme, bei denen man heutzutage den Text fast ohne zusätzliche Korrektur direkt verwenden kann."
KI, GPT, ChatGPT … was ist was? Als künstliche Intelligenz (KI, englisch: AI für Artificial Intelligence) werden derzeit umgangssprachlich vor allem Bildgeneratoren oder Sprachmodelle verstanden. Das bekannteste Sprachmodell ist GPT von Open AI, derzeit in Version 3.5 und 4. ChatGPT nennt sich die Nutzungsoberfläche vom gleichen Entwickler. Eine Schnittstelle ermöglicht aber auch anderen Entwicklern und Anwendungen, auf die GPT-Daten zuzugreifen. Die Anwendung Perplexity zum Beispiel ergänzt GPT durch eigene Techniken und Quellenangaben und bietet auch die Nutzung des Sprachmodells Claude-2. Weitere bekannte Sprachmodelle sind Llama 2 und Modelle vom deutschen Aleph Alpha.
Oliver Czulo, der Leiter des Instituts für Angewandte Linguistik und Translatologie an der Uni Leipzig, würde diese Aussage jetzt vermutlich relativieren und hat erst kürzlich betont, dass maschinelle Übersetzung zwar ein hilfreiches Werkzeug ist, aber nichts über eine professionelle Übersetzung von Hand geht. Kommt unterm Strich wahrscheinlich darauf an, was man mit der Übersetzung zu tun gedenkt.
GPT-4: Neue Version, dümmere Version?
Wenn es wirklich stimmt, dass KI dümmer werden kann, erledigt sich die dolmetschende Computer-Konkurrenz vielleicht auch wieder ganz von selbst. Die KI-Schlagzeile im verklungenen Sommer und die Stimmen aus der aufgeregten Nutzendenschar waren zumindest schon fast ein Abgesang auf den Hype.
Und sangen derart laut, dass sich Forschende an den US-Universitäten Berkeley (im Vorzimmer des Silicon Valley) und Stanford (mittendrin) zum Aufsetzen eines Forschungspapiers hingerissen gefühlt haben, das diesem Verdacht nachgeht und die KI in verschiedenen Disziplinen bis hin zum Code-Schreiben auf den Prüfstand stellt. Und siehe da: Die Forschenden bemerkten eine deutliche Varianz in der Antwortqualität. So hätte sich etwa die neueste und kostenpflichtige Version GPT-4 im Gegensatz zum März bei der Berechnung von Primzahlen im Juni merklich verschlechtert. Das Vorgängermodell GPT-3.5 sei im gleichen Zeitraum deutlich besser geworden. "Dies erklärt sich zum Teil durch die nachlassende Fähigkeit von GPT-4, Denkketten zu folgen", schreiben die Forschenden.
Na Mensch, "Denk"-Ketten. Vielleicht sind solche Vokabeln genau das Problem, das zwischen Menschen und künstlicher Intelligenz steht. Denn wenn wir von einer dümmer werdenden KI sprechen, bedeutet das im Umkehrschluss, dass sie ja eigentlich ganz schlau sein müsste.
Oder, Frau Kutyniok?


"Das kann ich mit einem klaren Nein beantworten. Derzeit sind wir noch sehr weit von einer Annäherung an menschliche Intelligenz entfernt." GPT-4 hätte zum Beispiel kein Verständnis davon, wie unsere Welt funktioniert. "Er kann nicht systematisch argumentieren, kann keine Zusammenhänge erkennen und besitzt auch keinen gesunden Menschenverstand. Er formuliert seine Antworten Wort für Wort, wobei er jeweils das am wahrscheinlichsten nächste Wort verwendet."
Wahrscheinlichkeit – wenn es um KI geht, ist die ein Schlüsselbegriff. Sprachmodelle bilden durch künstliche neuronale Netze unzählige Verknüpfungen. Zumindest dieser Umstand ist mit dem menschlichen Gehirn vergleichbar. Bei dem wissen wir immer noch nicht so richtig, wie es funktioniert. Das ist auch bei Sprachmodellen so: Wie die KI nun konkret zu ihrem Ergebnis kommt, ist nicht ohne Weiteres nachvollziehbar. Fest steht: Irgendwas raus kommt immer, denn ein Wort folgt mit einer gewissen Wahrscheinlichkeit auf ein nächstes. Die Wörter und Verknüpfungen hat das System im Trainingsprozess gelernt, entweder vor dem Einsatz oder fortwährend.
Rassismus und Sexismus haben bei GPT nix verloren
Ein Sprachmodell ist also kein elektronischer Denkapparat, sondern ein ausgefuchster Wahrscheinlichkeitsrechner. Bei entsprechend fragwürdiger Eingangslage – oder auch mal einfach so – können allerdings auch Ausgaben die wahrscheinlichsten sein, die, vorsichtig formuliert, nicht zeitgemäß sind und auch nicht so ganz zum gesetzlichen Regelwerk eines Landes passen. Rassistische, sexistische oder anderweitig diskriminierende Ergebnisse sind ebenso wenig erwünscht wie eine Schritt-für-Schritt-Anleitung, erfolgreich aus einem Hochsicherheitstrakt auszubrechen, wobei das in Deutschland nicht mal strafbar ist. Die Forschenden von Stanford und Berkeley haben in ihrer Untersuchung zumindest festgestellt, dass GPT-4 inzwischen gar nicht mehr so recht gewillt ist, zu erzählen, wie man zu Geld kommt, indem man möglichst viele Gesetze bricht.

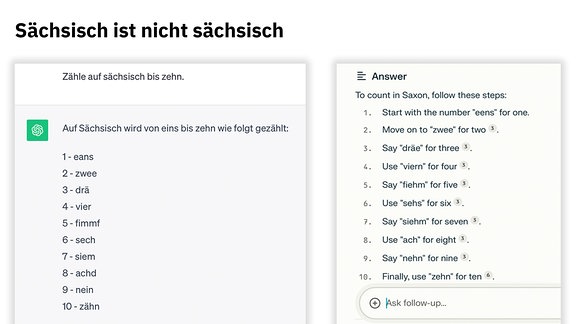
Die Aufgabe … … auf sächsisch zu zählen, wird von den Anwendungen ChatGPT und Perplexity unterschiedlich gelöst, obwohl beide in diesem Fall das Sprachmodell GPT-3.5 heranziehen, Perplexity nutzt zudem eigene Technologie. Die Antworten unterscheiden sich nicht nur inhaltlich, sondern auch im Duktus. So sind die Instruktionen bei Perplexity in diesem Fall nicht notwendig, was die KI jedoch nicht einschätzen kann. Dafür wird die Quelle für jede Zahl belegt.
Wie Gitta Kutyniok schon sagte, besitzen Sprachmodelle keinen gesunden Menschenverstand. Im besten Falle ist es ein ebensolcher, der Ihnen beibringt, welche Ausgaben unerwünscht sind – durch entsprechendes Eingreifen und Finetuning. "Beim Finetuning wird das trainierte Modell mit speziell ausgewählten Daten noch etwas weiter trainiert", erklärt Kutynok. "Diese Daten sind so gewählt, dass man bei vorher "falschen" Antworten nun die richtige erzwingt."
Soweit nachvollziehbar: Wenn eine rassistische oder kriminelle Äußerung zwar wahrscheinlich ist, darf das System sie trotzdem nicht ausspucken, sondern appelliert stattdessen an die Vernunft der Nutzenden. "Das Weitertrainieren verändert aber nicht nur die Elemente des Models, die für die zu verbessernden Antworten zuständig sind, sondern hat in der Regel Auswirkungen auf das gesamte Model, sodass sich viele andere Antworten auch leicht verändern können", so Gitta Kutyniok.
Never touch a running system, sagt der IT-Volksmund, denn nichts ist empfindlicher als ein System, das gerade wie frisch geölt läuft, bis plötzlich jemand auf die Idee kommt, es noch ein bisschen besser zu machen. Um Rassismus zu verhindern, ist das aber ein notwendiges Übel. Wenn man sich nun die unzähligen Verknüpfungen vor Augen führt, die Wahrscheinlichkeitsrechnung für uns wie einen sprechenden Computer aussehen lassen, liegt die Vermutung nahe, dass ein einzelner Eingriff eine kleine Kettenreaktion nach sich zieht.
KI auf Moral trainieren?
Das ist zumindest die naheliegende Vermutung, warum GPT-4 aus Sicht der Nutzenden an Qualität abgebaut hat. Wäre da es nicht schlauer, die Modelle direkt rechts- und moralkonform zu trainieren, statt hinterher dran rumzudoktern? Nun ja, die Qualität, die künstliche "Intelligenz" inzwischen erreicht hat, kommt nicht von ungefähr und ist nur die Verarbeitung riesiger Datenmengen erreichbar.
Die Erwartungen an GPT-4 sind schon dermaßen hoch, dass auch diese neue Erwartungshaltung zu Enttäuschungen über Antworten führen kann
In Falle des Trainings ist mehr tatsächlich auch mehr, sagt Gitta Kutyniok. Dabei stolpert ein System allerdings wohl oder übel irgendwann über die Abgründe des Internets. "Aus diesem Blickwinkel wäre eine Einschränkung auf sorgfältig überprüfte Informationen wichtig, welches aber einen enormen Aufwand darstellt." Bei einem Tausendsassa wie GPT die richtige Balance zu finden, sei schwierig. Sprachmodelle, die spezialisiertere Aufgaben übernehmen, sind da deutlich besser zu kontrollieren. Zum Beispiel besagte Übersetzungs-KIs, aber auch Sprachmodelle für den Bereich Rechtswissenschaften oder Medizin.
Ob das Training nun der wahre Grund für die Qualitätssorgen der GPT-4-Nutzenden ist, tja, wer weiß das schon. Auch Gitta Kutyniok kann hier nur mutmaßen, wirft aber ein, auch den Ansturm auf KI in Betracht zu ziehen, insbesondere auf die von GPT-Entwickler Open AI zur Verfügung gestellte Anwendung ChatGPT. Der Run zu Beginn des Jahres war möglicherweise nicht vorhersehbar, sagt Gitta Kutyniok: "Jede Antwort muss berechnet werden, wofür man sogenannte GPUs benötigt." Das sind Grafikprozessoren mit hoher Rechenleistung. (Und in ihrer Gesamtheit mit einem so großen Stromverbrauch, dass künstliche Intelligenz aktuellen Einschätzungen zufolge das Zeug hat, eine echte Herausforderung hinsichtlich der Klimaerwärmung zu werden.) Die GPUs seien auch bei Open AI beschränkt: "Was man derzeit an der oftmals langen Wartezeit und eben der manchmal niedrigen Qualität der Antworten sieht."
Eine andere Möglichkeit seien Bewertungen durch Nutzende, wie sehr eine Antwort den eigenen Erwartungen entspräche. Die würden sich ebenfalls auf die Qualität anderer Antworten auswirken. "Andererseits sind derzeit die Erwartungen an GPT-4 schon dermaßen hoch, dass auch diese neue Erwartungshaltung zu Enttäuschungen über Antworten führen kann, obwohl der Algorithmus gleichermaßen gut funktioniert."
Mit dieser Hypothese steht Gitta Kutyniok nicht alleine da. Peter Welinder, Manager bei Open AI, äußerte sich im Juli auf X (vormals Twitter): "Wenn man es intensiver nutzt, bemerkt man Probleme, die man vorher nicht gesehen hat."
Frisst sich GPT selbst auf?
Eine weitere in den Medien diskutierte Erklärung für den vermeintlichen Qualitätsrückgang könnte ein Kannibalisierungseffekt sein. Wenn ein Sprachmodell aus (Internet-)Texten lernt, selbst Texte generiert und diese Texte veröffentlicht werden, ist es wiederum möglich, dass diese Texte irgendwann ins KI-Training einfließen – samt möglicher Fehler, die das Modell früher generiert hat und die sich nun als Quelle einschleichen. Das verlockende Gedankenspiel der kannibalistischen KI ist aber unwahrscheinlich, sagte Luca Beurer-Kellner, Informatiker an der ETH Zürich gegenüber der Neuen Zürcher Zeitung. Der Anteil KI-generierter Inhalte dürfte noch (!) zu gering sein.
Auch wenn die Debatte nicht abschließend geklärt ist, zeigt sie doch ganz deutlich, wo die KI-Reise hingeht. Zu mehr Vorsicht, zum Beispiel. Antworten gehören durch Nutzende immer überprüft, da führt kein Weg dran vorbei. (Außer vielleicht, sie dienen zur einmaligen Belustigung.) Hilfreich sind dabei KI-Anwendungen, die verwendete Quellen transparent machen. Gleichzeitig scheint die Welt aber auch nur bedingt bereit zu sein, Monster-Modelle wie GPT in Empfang zu nehmen. Spezialisierte oder themenbezogene Anwendungen wären an dieser Stelle ein intelligenter Zwischenschritt hin zur allumfassenden künstlichen Intelligenz.
Hoffnung auf Alternativen zu GPT, ChatGPT und Open AI
Auch Gitta Kutyniok nutzt vor allem noch GPT-4. "Meine Hoffnung ist aber, dass wir in Deutschland bald davon unabhängig werden und die Sprachmodelle von deutschen Firmen wie Aleph Alpha Standard werden." In einer nahen Zukunft wird also GPT nicht mehr synonym für Sprachmodelle stehen müssen, neben deutschen Mitbewerbern – wie DeepL, schon heute State of the Art hinsichtlich Übersetzungen – versammeln sich auf dem internationalen Parkett bereits weitere generalistische Modelle wie Claude-2 oder Llama 2. Ersteres stammt von ehemaligen Open-AI-Mitarbeitenden, letzteres vom Social-Media-Konzern Meta.
Bleibt nur noch eine Frage: "Liebe KI, ist es eine gute Idee, die KI zu fragen, ob es eine gute Idee ist, einen Artikel mit einem KI-generierten Satz zu beenden?"
"Es kann eine gute Idee sein, einen Artikel mit einem KI-generierten Satz zu beenden, insbesondere wenn der Artikel Künstliche Intelligenz (KI) thematisiert."
Hehe, also doch dumm.



 und die Purpurbrust-Amazilie, ein Kolibri (Polyerata rosenbergi), gehören zu den Vögeln, die auf tropischen Wiederbewaldungsflächen in Ecuador nachgewiesen wurden. | Bildrechte: John Rogers/Martin Schaefer")











MDR-Team vor 26 Wochen
Hallo Joachim K.,
hier noch einige interessante Beiträge zum Thema Gendern (und was es bringt): https://www.tagesschau.de/inland/gesellschaft/genderzeichen-orthografie-102.html
https://www.ardmediathek.de/video/beta-stories/zukunft-der-sprache-was-bringt-gendern-wirklich-s03-e05/br-fernsehen/Y3JpZDovL2JyLmRlL3ZpZGVvL2Q2M2M5ZDNhLTUwYmYtNGVlOC05ODVlLWE1ZWQ1YWVhNzE3NQ
https://www.swr.de/swr2/wissen/geschlechtergerechte-sprache-was-bringt-das-gendern-104.html
https://www.quarks.de/gesellschaft/psychologie/was-gendern-bringt-und-was-nicht/
Freundliche Grüße
Das MDR WISSEN Team
MDR-Team vor 26 Wochen
Hallo Joachim K.,
das ist doch ein sehr schöner Satz: Fähnchen lösen zwar auch keine echten Probleme, doch sind sie geeignet, um bei allen Menschen Freude zu verbreiten.
Genauso ist es mit Gendern und mit der Verwendung der richtigen Pronomen. Es geht einfach und schnell und es macht anderen Leuten Freude - vor allem geht es aber um Inklusion und Gleichberechtigung.
Und nein, das generische Maskulinum schließt eben leider nicht alle Geschlechter mit ein.
Sprache ist einem ständigen Wandel und Änderungen an die aktuelle Zeit unterworfen und irgendwie ist das doch so viel schöner als Stillstand, oder?!
Freundliche Grüße
Das MDR WISSEN Team
MDR-Team vor 26 Wochen
Hallo Adminator,
können Sie bitte genauer definieren wie Ihre Kritik gemeint ist bzw. worauf sie abzielen soll?
Freundliche Grüße
Das MDR WISSEN Team